LRU 基础
内存的数据是有限的,因此不可能无限制地添加数据。假定我们设置缓存能够使用的内存大小为 N,那么在某一个时间点,添加了某一条缓存记录之后,占用内存超过了 N,这个时候就需要从缓存中移除一条或多条数据了。那移除谁呢?我们肯定希望尽可能移除“没用”的数据,那如何判定数据“有用”还是“没用”呢?
FIFO/LFU/LRU 算法简介
FIFO(First In First Out)
先进先出,也就是淘汰缓存中最老(最早添加)的记录。FIFO 认为,最早添加的记录,其不再被使用的可能性比刚添加的可能性大。这种算法的实现也非常简单,创建一个队列,新增记录添加到队尾,每次内存不够时,淘汰队首。但是很多场景下,部分记录虽然是最早添加但也最常被访问,而不得不因为呆的时间太长而被淘汰。这类数据会被频繁地添加进缓存,又被淘汰出去,导致缓存命中率降低。
LFU(Least Frequently Used)
最少使用,也就是淘汰缓存中访问频率最低的记录。LFU 认为,如果数据过去被访问多次,那么将来被访问的频率也更高。LFU 的实现需要维护一个按照访问次数排序的队列,每次访问,访问次数加1,队列重新排序,淘汰时选择访问次数最少的即可。LFU 算法的命中率是比较高的,但缺点也非常明显,维护每个记录的访问次数,对内存的消耗是很高的;另外,如果数据的访问模式发生变化,LFU 需要较长的时间去适应,也就是说 LFU 算法受历史数据的影响比较大。例如某个数据历史上访问次数奇高,但在某个时间点之后几乎不再被访问,但因为历史访问次数过高,而迟迟不能被淘汰。
LRU(Least Recently Used)
最近最少使用,相对于仅考虑时间因素的 FIFO 和仅考虑访问频率的 LFU,LRU 算法可以认为是相对平衡的一种淘汰算法。LRU 认为,如果数据最近被访问过,那么将来被访问的概率也会更高。LRU 算法的实现非常简单,维护一个队列,如果某条记录被访问了,则移动到队尾,那么队首则是最近最少访问的数据,淘汰该条记录即可。
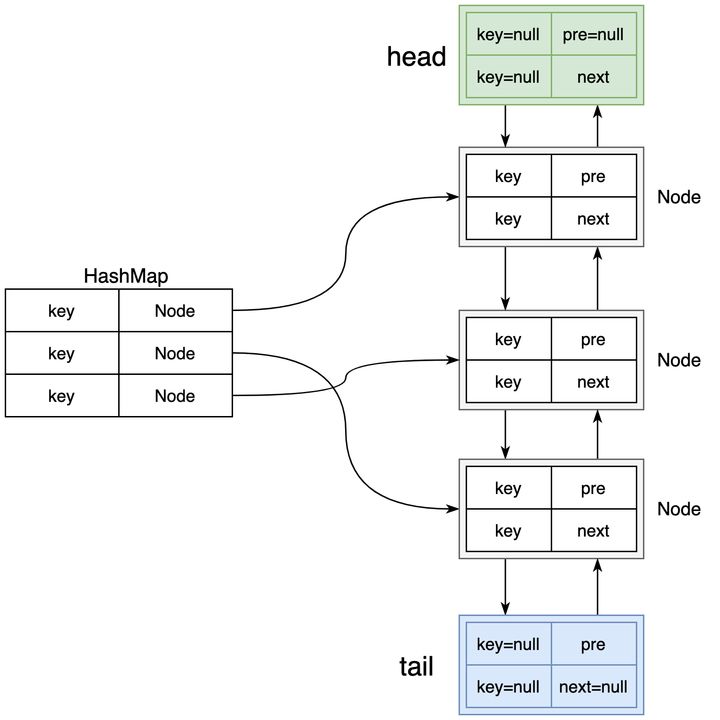
实现一个 LRU 需要用到一个哈希表和一个双向链表。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
- LRU 要点:删除都在表尾,添加都在表头,维护 dummy_head 和 dummy_tail ,
- 成员变量: cache, size, capacity; 头尾指针|如果用list,自带head和tail
- 方法:
- 创建节点(到头); 删除一个节点
- 访问一个节点(原来位置的node 删除,把node移动到头) ; 删除尾部 (optional)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| struct DLinkedNode {
int key, value;
DLinkedNode* prev;
DLinkedNode* next;
DLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr) {}
DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr) {}
};
class LRUCache {
private:
unordered_map<int, DLinkedNode*> cache;
DLinkedNode* head;
DLinkedNode* tail;
int size;
int capacity;
public:
LRUCache(int _capacity): capacity(_capacity), size(0) {
head = new DLinkedNode();
tail = new DLinkedNode();
head->next = tail;
tail->prev = head;
}
int get(int key) {
if (!cache.count(key)) {
return -1;
}
DLinkedNode* node = cache[key];
moveToHead(node);
return node->value;
}
void put(int key, int value) {
if (!cache.count(key)) {
DLinkedNode* node = new DLinkedNode(key, value);
cache[key] = node;
addToHead(node);
++size;
if (size > capacity) {
DLinkedNode* removed = removeTail();
cache.erase(removed->key);
delete removed;
--size;
}
}
else {
DLinkedNode* node = cache[key];
node->value = value;
moveToHead(node);
}
}
void addToHead(DLinkedNode* node) {
node->prev = head;
node->next = head->next;
head->next->prev = node;
head->next = node;
}
void removeNode(DLinkedNode* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
void moveToHead(DLinkedNode* node) {
removeNode(node);
addToHead(node);
}
DLinkedNode* removeTail() {
DLinkedNode* node = tail->prev;
removeNode(node);
return node;
}
};
|
使用 std::list 实现LRU,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| #include <iostream>
#include <unordered_map>
#include <list>
using namespace std;
class LRUCache {
private:
int capacity;
unordered_map<int, pair<int, list<int>::iterator>> cache;
list<int> recent;
public:
LRUCache(int capacity) {
this->capacity = capacity;
}
int get(int key) {
if (cache.find(key) != cache.end()) {
updateRecent(key);
return cache[key].first;
}
return -1;
}
void put(int key, int value) {
if (cache.find(key) != cache.end()) {
updateRecent(key);
cache[key].first = value;
} else {
if (cache.size() >= capacity) {
evict();
}
recent.push_front(key);
cache[key] = {value, recent.begin()};
}
}
private:
void updateRecent(int key) {
recent.erase(cache[key].second);
recent.push_front(key);
cache[key].second = recent.begin();
}
void evict() {
int evictKey = recent.back();
cache.erase(evictKey);
recent.pop_back();
}
};
int main() {
LRUCache cache(2);
cache.put(1, 1);
cache.put(2, 2);
cout << cache.get(1) << endl;
cache.put(3, 3);
cout << cache.get(2) << endl;
cache.put(4, 4);
cout << cache.get(1) << endl;
cout << cache.get(3) << endl;
cout << cache.get(4) << endl;
return 0;
}
|
LRU 实现注意:
- 不要忘记及时更新map,map这里最好用emplace, 不要用
[]来添加元素
- 双向链表把节点添加到head需要4步
- put时元素若存在,也需要更新它的value
- 我的写法:两种成员方法, add2head(非新节点要把老位置的删掉) 和 evict(删除节点) 就够了
深入理解 LRU
LRU-K & 2Q
LRU算法实现虽然简单,并且在大量频繁访问热点页面时十分高效,但同样也有一个缺点,就是如果该热点页面在偶然一个时间节点被其他大量仅访问了一次的页面所取代,那自然造成了浪费。
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。
LRU-K的主要目的是为了解决LRU算法缓存污染的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使
用过K次”。
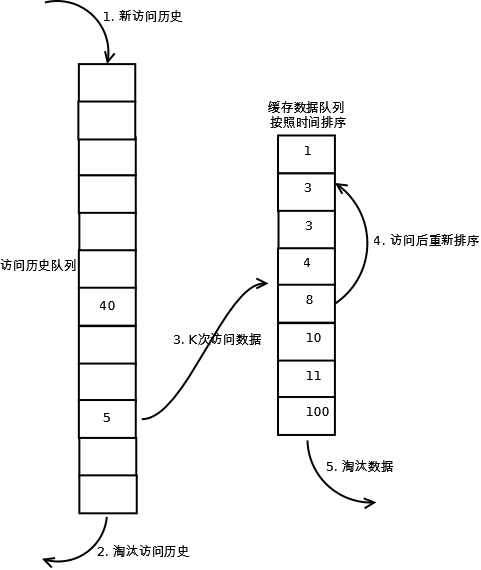
LRU 需要维护两个队列:历史队列和缓存队列。
简单来说,如果历史队列中的元素被访问了 K 次,它会离开历史队列前往缓存队列。缓存队列的元素就没那么容易被随便淘汰,抗干扰能力就强一些。
LRU workflow

LRU-K的历史队列和缓存队列在满时的更新策略可以自由选择
LFU 可以理解为 k = ∞ 的 LRU-K 算法。
2Q 算法是一种具体的 LRU-2 算法,其历史队列采用FIFO,缓存队列采用LRU-1。
LRU-K的性能:K = 2可能是最常用也最好用的。
redis 的 LRU 实现
由于 LRU 算法需要用链表管理所有的数据,会造成大量额外的空间消耗。
除此之外,大量的节点被访问就会带来频繁的链表节点移动操作,从而降低了 Redis 性能。
所以 Redis 对该算法做了简化,Redis LRU 算法并不是真正的 LRU,Redis 通过对少量的 key 采样,并淘汰采样的数据中最久没被访问过的 key。
这就意味着 Redis 无法淘汰数据库最久前访问的数据
Redis LRU 算法 可以更改样本数量来调整算法的精度,使其近似接近真实的 LRU 算法,同时又避免了内存的消耗,因为每次只需要采样少量样本,而不是全部数据。
LFU, Least Frequently Used
本质上就是访问次数最少的滚蛋,访问次数一样少的就按照时间来淘汰。所以每个node都需要一个时间戳和一个访问计数器。
法一(慢的很):
用std::set 来充当AVL tree,每个节点创建 freq 和 时间戳,重载一下operator,这时 set 就会默认按照 1.访问次数 2. 访问时间 排序了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| struct node
{
int key, value, freq = 1, t;
node(int k, int v, int f, int t): key(k), value(v), freq(f), t(t) {}
bool operator < (const node& rhs) const {
return freq == rhs.freq ? t < rhs.t : freq < rhs.freq;
}
};
class LFUCache {
private:
set<node> s;
unordered_map<int, node> cache;
int capacity, time;
public:
LFUCache(int capacity) : capacity(capacity), time(0) {
s.clear();
cache.clear();
}
int get(int key) {
if (capacity == 0) return -1;
time++;
auto it = cache.find(key);
if (it == cache.end()) {return -1;}
auto cur_node = it->second;
s.erase(cur_node);
cur_node.freq++;
cur_node.t = time;
s.insert(cur_node);
it->second = cur_node;
return cur_node.value;
}
void put(int key, int value) {
time++;
if (capacity == 0) {return;}
auto it = cache.find(key);
if (it == cache.end()) {
if (s.size() == capacity) {
cache.erase(s.begin()->key);
s.erase(s.begin());
}
node cur_node = node(key, value, 1, time);
s.insert(cur_node);
cache[key] = cur_node;
} else {
auto cur_node = it->second;
s.erase(cur_node);
cur_node.freq++;
cur_node.t = time;
cur_node.value = value;
s.insert(cur_node);
it->second = cur_node;
}
}
};
|
LFU实现注意:
- 注意同时更新hash map,尽量用insert或者emplace来添加元素
- 用set来存node,在node的结构体里定义operator,这时set就是有序的
- 在添加node之前,先检查满了没,不要先插入再删除,这样会把刚刚添加的node踢掉
其他资料: